2026 : Faut-il (enfin) migrer vers Microsoft Fabric ? Mon verdict d'Architecte
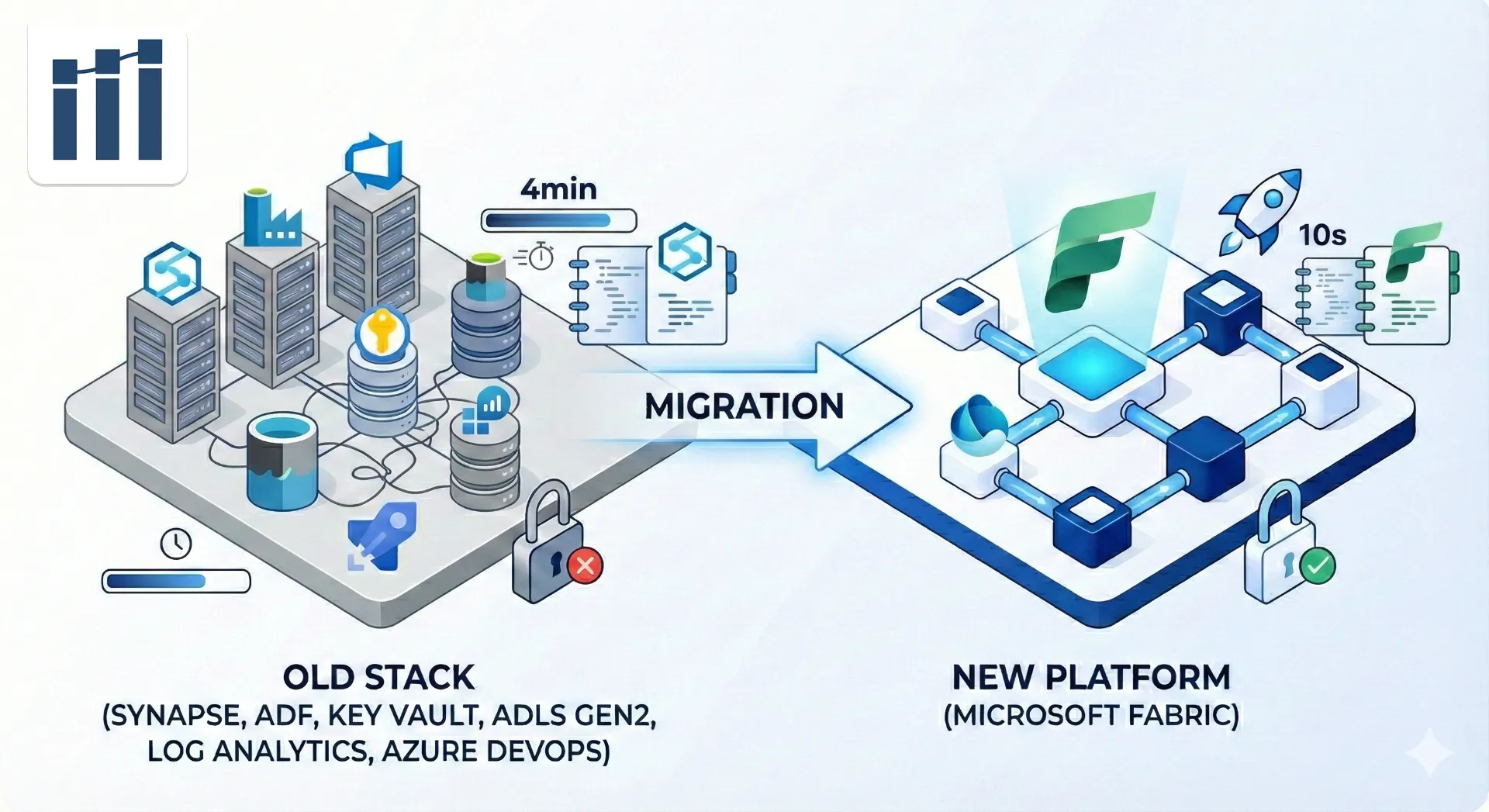
2026 Enfin la bonne année pour migrer d'Azure Synapse Analytics vers Microsoft Fabric ?
On a longtemps attendu. On a beaucoup comparé (et testé avec des licences trial de 60 jours toujours repoussées).
Mais en cette année 2026, la plateforme a atteint un niveau de maturité qui change la donne.
Pendant des années, sur Azure Synapse Analytics et ADF, on a appris à vivre avec certaines douleurs : les temps de démarrage de Spark, la complexité de la sécurité ou encore la lourdeur des déploiements. Aujourd'hui, après quelques projets migrés et optimisés sur Microsoft Fabric, le constat est sans appel.
Ce n'est pas juste une mise à jour, c'est la correction de pas mal des dettes techniques qui ralentissaient les équipes Data. Voici mon retour d'expérience (sans filtre marketing, j'ai rien à vendre) sur pourquoi la migration est devenue peut-être une évidence technique dans certains cas.
1. CI/CD et DevOps : La fin du bricolage
Si vous avez géré des pipelines de déploiement sur Synapse, vous savez à quel point c'était laborieux. Fabric a radicalement simplifié l'expérience développeur (DX).
Adieu l'enfer des DACPACs : Gérer le déploiement incrémental d'un Dedicated SQL Pool via des DACPACs dans Azure DevOps était une source constante d'erreurs et de stress. On ne compte pas les paramétrages ou les objets qui finissaient systématiquement écrasés. Sur le Warehouse Fabric, cette complexité a disparu. Le moteur gère les différences de schéma bien plus fluidement (Merci Microsoft).
Git Integration "Live" : Fini le bouton "Publish" anxiogène d'ADF ou Synapse pour sauvegarder son travail, là encore nombreux étaient les bugs qui forçaient une resynchronisation complète du workspace. Le Source Control est natif maintenant dans Fabric. On code, on commit, c'est synchronisé. On ne bloque plus les collègues et on ne casse plus (ou peu).
Pipelines de déploiement natifs : Plus besoin de construire des pipelines YAML complexes dans Azure DevOps (avec des extensions pas forcément maintenues régulièrement) pour orchestrer le passage de Dev à Prod. Les Deployment Pipelines sont intégrés directement dans l'interface Fabric, visuels et efficaces. Des règles de déploiement sont également disponibles afin de variabiliser certains éléments c'est basique, simple mais suffisant.
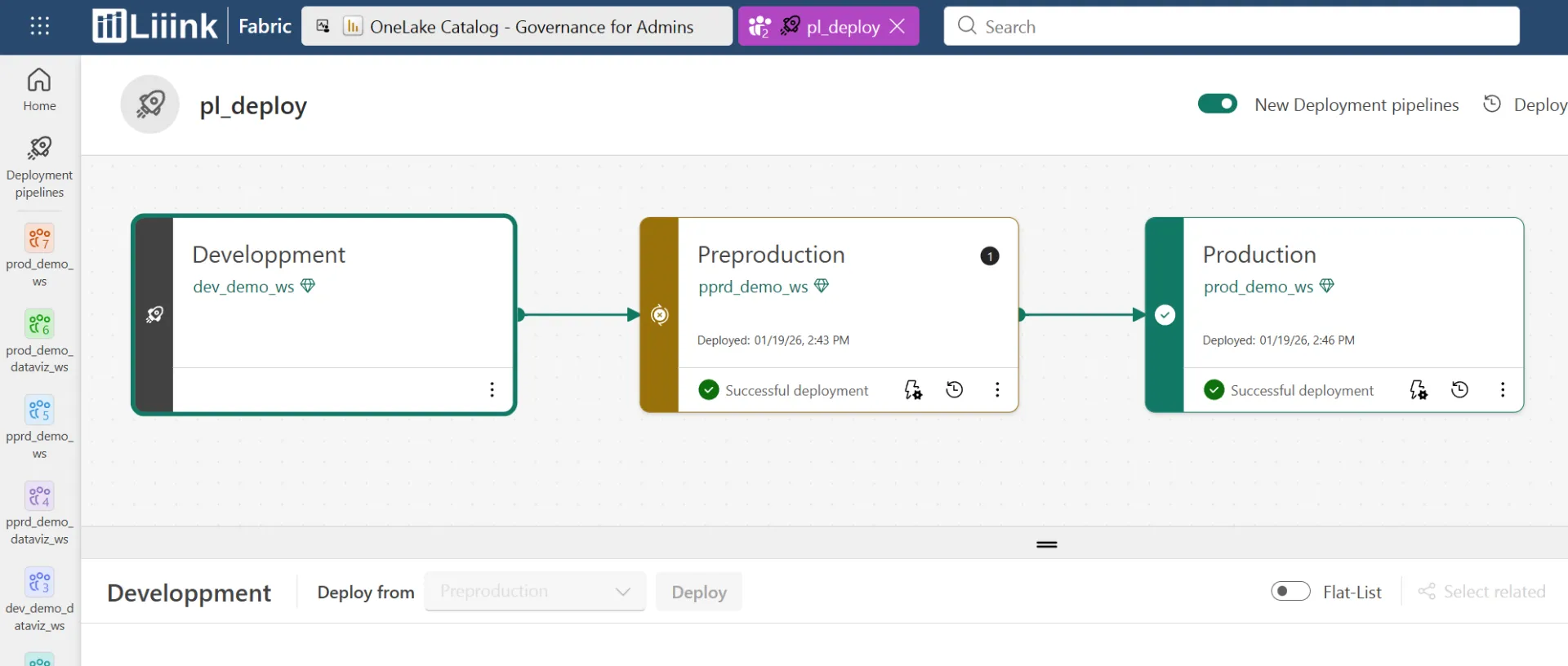
2. Gestion des environnements : Enfin propre
C'est peut-être le changement qui a le plus nettoyé mon code.
La fin des KeyVaults à outrance : Sur Synapse, chaque environnement nécessitant sa(ses) propre(s) chaîne(s) de connexion, on finissait avec des KeyVaults partout. Sur Fabric, on attache un Lakehouse à un notebook comme on monterait un disque.
Chemins relatifs : J'utilise désormais des chemins relatifs dans mon code. Le contexte d'exécution (Dev, Test, Prod) bascule automatiquement sur la bonne donnée suivant les workspaces Fabric. C'est transparent, sécurisé et ça allège considérablement la configuration et le code.
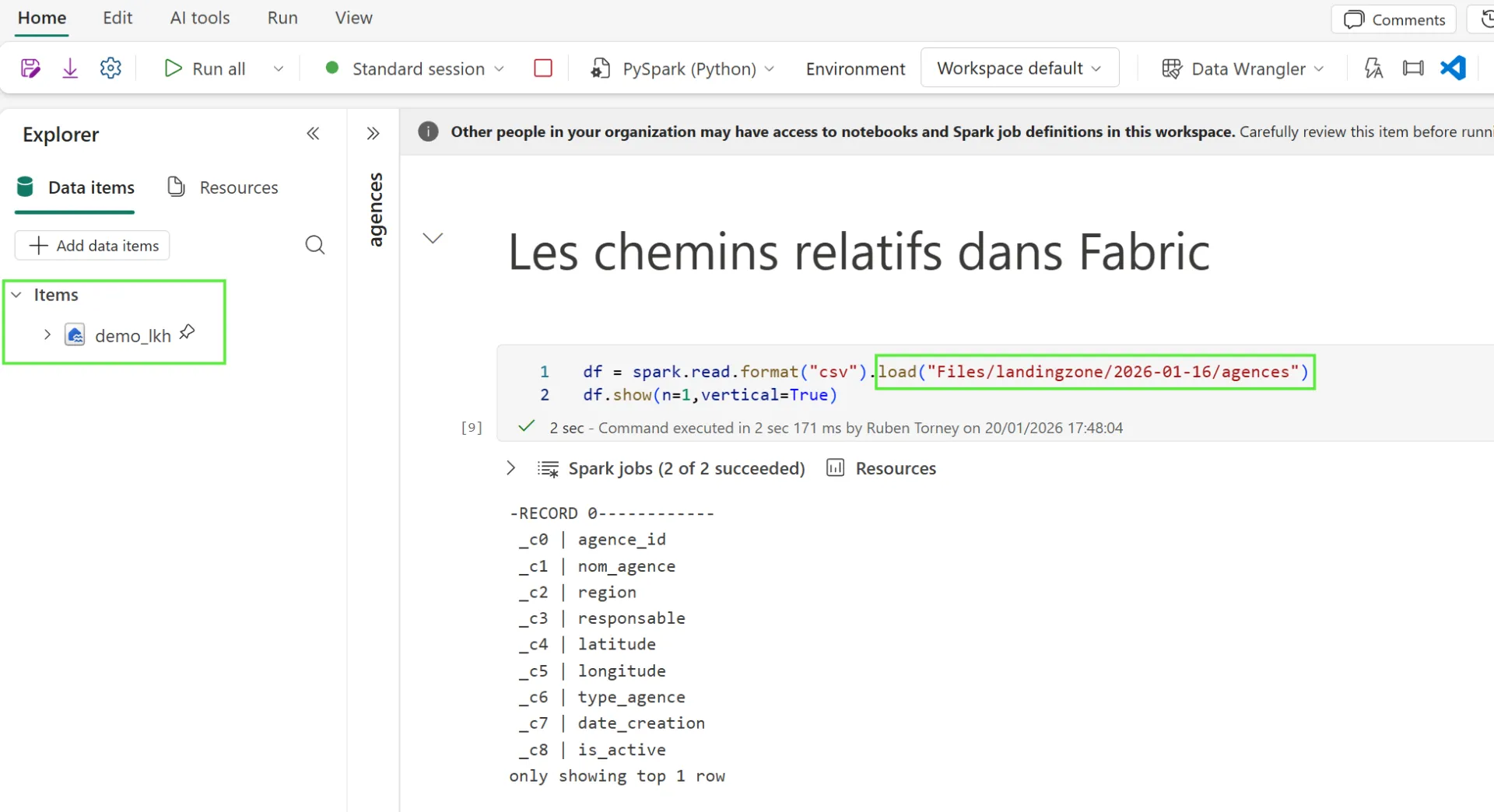
3. Spark : Un immense bond
C'est le gain de productivité le plus visible au quotidien pour un Data Engineer.
Démarrage en 6 secondes (vs 4 min) : Sur Synapse, lancer une session prenait le temps d'aller prendre un café (3 à 4 min). Sur Fabric, les Starter Pools optimisés démarrent en moins de 10 secondes. Sur une journée de développement, on gagne littéralement une heure voire plus.
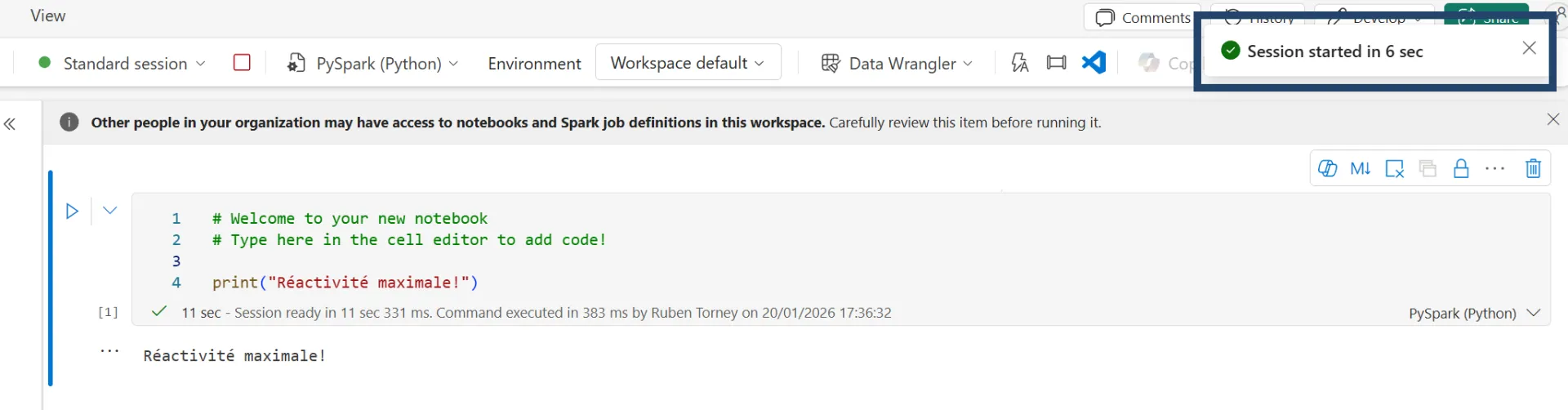
High Concurrency Sessions : Une fonctionnalité qui manquait cruellement à Synapse. On peut enfin gérer la concurrence proprement sur les notebooks sans avoir à multiplier les clusters ou gérer des files d'attente interminables (10min pour bouger 5 parquets c'est possible dans Synapse malheureusement).
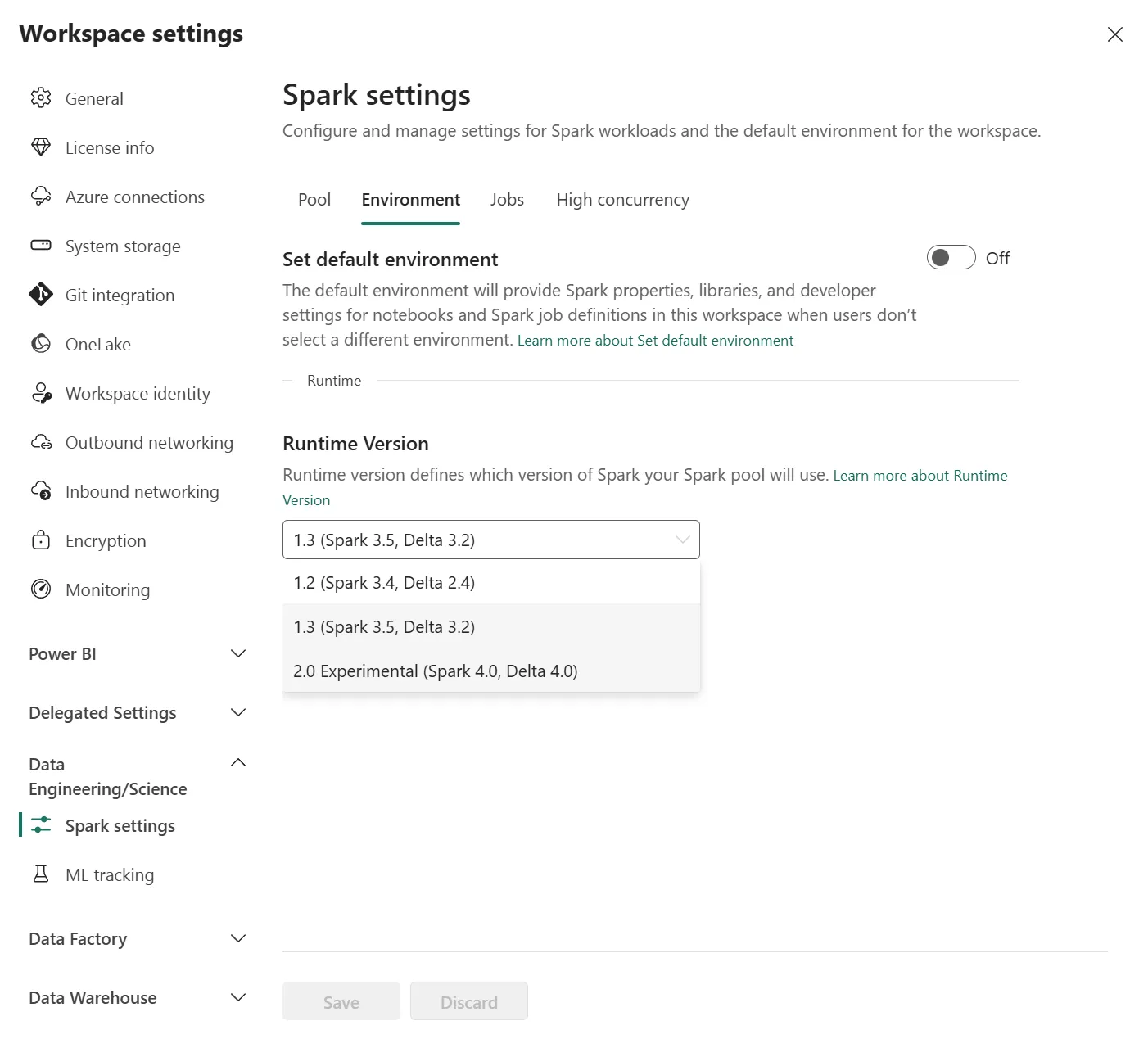
Version plus récente de Spark et Delta : C'est ici que le fossé se creuse. Sur Synapse, nous avons longtemps été bloqués sur des versions Spark 3.1 ou 3.2, avec des mises à jour très lentes à arriver. Je garde un souvenir douloureux de la migration forcée de Spark 3.1 vers 3.2 : un processus à peine documenté, des librairies qui cassaient silencieusement et une équipe pas franchement rassurée au moment de basculer la Prod.
Sur Fabric, le rythme est tout autre. Nous sommes déjà sur Spark 3.5 (Runtime 1.3) et la préversion de Spark 4.0 est déjà disponible. Cela nous donne accès immédiatement aux dernières innovations :
Spark Connect : L'architecture découplée qui permet enfin de connecter proprement un IDE local (VS Code) au cluster distant.
Delta Lake Universal Format (UniForm) : Pour que nos tables Delta soient lisibles par des outils Iceberg ou Hudi sans duplication.
Optimisation V-Order : Des temps de lecture drastiquement réduits pour Power BI, activés par défaut.
Plus le temps passe, plus le décalage technique entre un Synapse vieillissant et un Fabric sous stéroïdes devient un risque pour la maintenabilité des projets.
4. Architecture & Stockage : droit au but
L'infrastructure laisse de plus en plus place à la logique data.
OneLake & Storage Accounts : Fini la création manuelle des comptes de stockage, la gestion de leur hiérarchie et tout ce qui va avec. Grâce à OneLake, le stockage est provisionné automatiquement sans se soucier de quoi que ce soit.
Tout en Delta (et V-Order) : Lakehouse ou Warehouse, le format natif est le Delta Parquet. On profite des optimisations de lecture (V-Order) par défaut, sans avoir à être un expert en tuning de fichiers. Les perfs sont là, dès le départ.
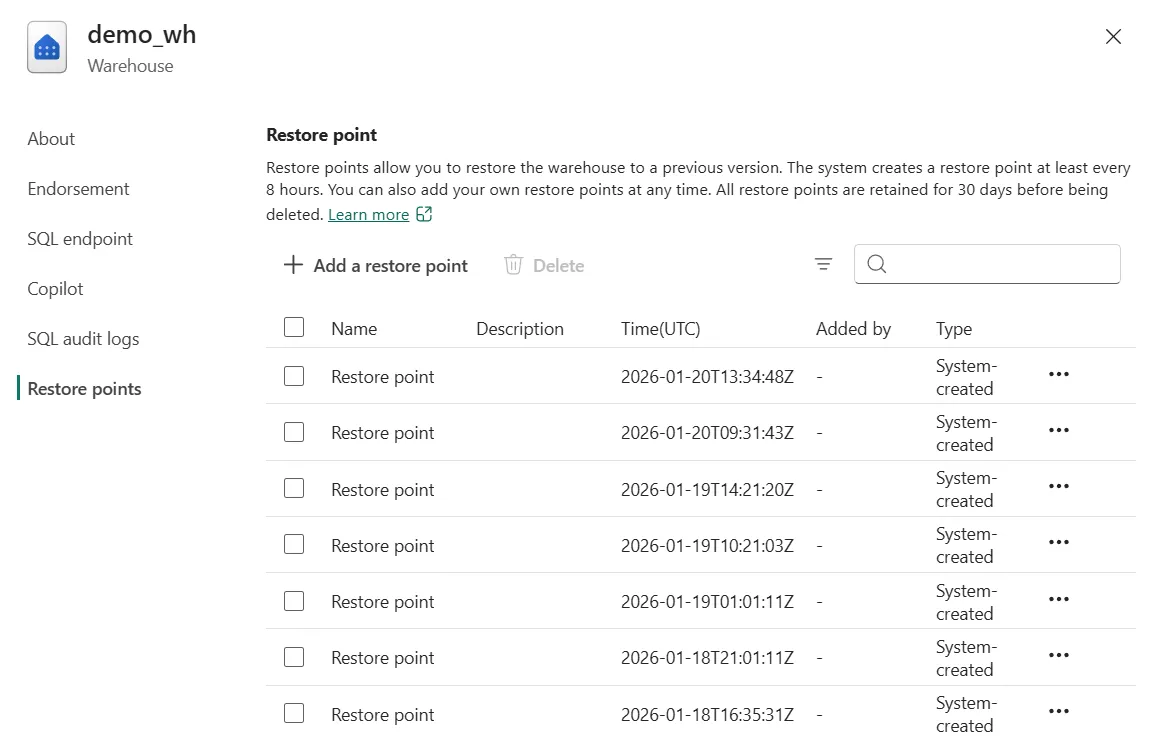
Maintenance du Warehouse : Comparé à un Dedicated SQL Pool qui demandait une maintenance d'index et de statistiques rigoureuse et une distribution des tables réglée aux petits oignons, le Warehouse Fabric "s'auto gère" beaucoup mieux. On retrouve un entrepôt de données très performants intégrant toutes les fonctionnalités SQL essentiels d'un pool dédié Synapse.
5. Sécurité : La fin de la "double peine" (RBAC + ACLs)
C'était le point noir absolu de l'architecture Synapse moderne. Sécuriser un projet demandait d'aligner trois couches non synchronisées : le Workspace, le SQL et surtout le stockage (RBAC + ACLs éventuellement).
Sécurité "By Design" : Dans Fabric, la sécurité est cohérente. Un rôle dans le Workspace donne les accès logiques nécessaires et basta.
Fini les conflits d'écriture : Plus besoin de configurer manuellement des rôles Storage Blob Data Contributor ou de se battre avec les ACLs pour qu'une Managed Identity puisse écrire un simple fichier CSV. L'identité est propagée, la sécurité est unifiée et simplifiée.
6. Nouvelles fonctionnalités & Monitoring
Activités Natives : C'est la fin des appels API bricolés avec des Web Activities pour des tâches simples. L'envoi de messages Teams, de mails ou le refresh de datasets Power BI se fait via des activités natives. Plus besoin de gérer des Service Principals juste pour rafraîchir un rapport!
Temps réel simplifié (Real-Time Intelligence) : Faire du temps réel avec l'ancien socle technique voulait dire monter une usine à gaz : Azure Stream Analytics (avec son langage spécifique) ou des clusters Spark Streaming coûteux qui tournent H24. Dans Fabric, l'arrivée des Eventstreams permet de brancher du Kafka ou de l'IoT Hub en mode "no-code" et d'ingérer ça direct dans un Eventhouse (KQL Database). C'est intégré, c'est fluide, et on a même Data Activator (Reflex) pour déclencher des alertes sans écrire une seule ligne de code et ça c'est une "feature" plutôt intéressante.
Monitoring Unifié : Le Monitoring Hub offre une vision claire des logs et de l'utilisation des ressources. L'utilisation de Log Analytics (souvent complexe et cher) n'est plus un prérequis obligatoire pour avoir de la visibilité, comme c'était le cas à "l'époque".
Conclusion : Est-ce le temps de la migration?
Microsoft a clairement accéléré sur les outils de transition. Presque tout est prêt aujourd'hui pour migrer les Dedicated Pools Synapse vers Fabric sans trop de douleur (le gros du travail est automatisé, notamment grâce à des utilitaires de migration).
En 2026, rester sur une stack Synapse/ADF n'est pas une "faute" en soi, surtout si elle tourne. Mais il faut être lucide : Synapse est en soins palliatifs. Les mises à jour s'espacent, les nouvelles fonctionnalités (comme Spark 4.0 ou les Eventhouses) ne lui sont pas destinées.
Rester figé, c'est accepter d'accumuler de la dette technique chaque jour un peu plus. Le gain en confort de développement (VS Code, Git), la simplification radicale de la sécurité et la vitesse d'exécution justifient à eux seuls le saut.
Pour un architecte, c'est l'opportunité de se concentrer enfin sur la valeur de la donnée (Architecture Médaillon, Qualité, Métier, Gouvernance) plutôt que de passer ses journées à faire de la plomberie Azure.
Vous avez des questions sur la stratégie de migration, sur le coût des capacités Fabric ou sur un point technique précis ? Contactez-nous.